Demystifying Distributed Data Parallel (DDP): A Journey from First Principles
If you’ve ever trained a large model across multiple GPUs, you know the drill: wrap your model in PyTorch’s DistributedDataParallel (DDP), bump up your batch size, and watch the loss go down. But under the hood, scaling isn’t magic. It’s a constant battle against the communication bottleneck.
I recently decided to build my own DDP implementation from scratch to really understand how to squeeze every bit of performance out of the network. What started as a “simple” exercise in overlapping compute and communication turned into a deep dive into CUDA streams, zero-copy memory buffers, and the lies that async_op=True tells you.
Here is the journey of how I went from a naive DDP implementation to a fully optimized, stream-overlapped, bucketed DDP.
1. The Baseline: Naive DDP
At its core, DDP is simple: you copy your model across multiple GPUs, give each GPU a different slice of the data, run the forward and backward passes, and then average the gradients across all GPUs before taking an optimizer step.
Here is the most basic way we could implement this:
class NaiveDDP(nn.Module):
def __init__(self, module: nn.Module) -> None:
super().__init__()
self.module = module
def forward(self, *inputs, **kwargs):
return self.module(*inputs, **kwargs)
def _allreduce_gradients(self):
world_size = dist.get_world_size()
for param in self.module.parameters():
if param.grad is not None:
dist.all_reduce(param.grad.data, op=dist.ReduceOp.SUM)
param.grad.data /= world_size
@contextlib.contextmanager
def backward_and_sync(self):
yield # loss.backward() happens here
self._allreduce_gradients()In this setup, we wait for the entire backward pass to finish before we start communicating.
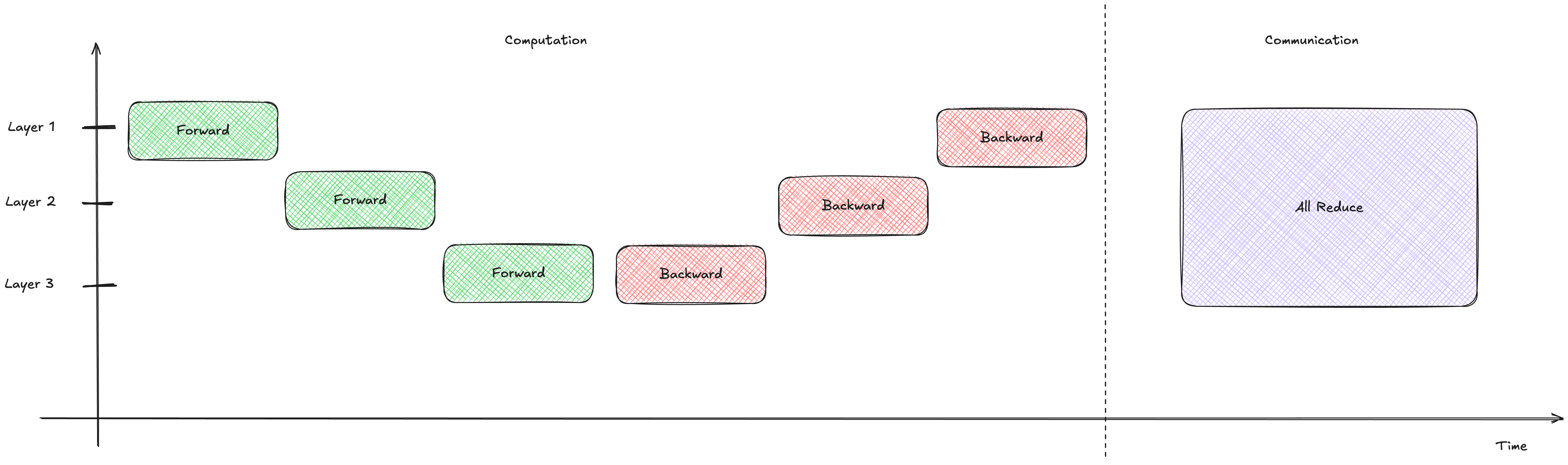 Notice how the communication (purple) only starts after all the computation (red) is completely finished.
Notice how the communication (purple) only starts after all the computation (red) is completely finished.
 Looking at the timeline, the GPU sits idle during the communication phase. This is a massive waste of time!
Looking at the timeline, the GPU sits idle during the communication phase. This is a massive waste of time!
The Problem: Compute and communication happen strictly sequentially. The network bandwidth is completely unused during the backward pass, and the GPU compute cores are twiddling their thumbs during the all-reduce phase.
2. Overlapped Synchronous DDP: Hooking into the Backward Pass
How can we do better? Well, the gradients for the later layers (closer to the output) are computed first during the backward pass. Why wait for the first layer’s gradients to be computed before we start sending the last layer’s gradients across the network?
PyTorch gives us a handy tool: register_post_accumulate_grad_hook. We can attach a hook to every parameter that fires the moment its gradient is ready!
class OverlappedSyncDDP(nn.Module):
def __init__(self, module: nn.Module) -> None:
super().__init__()
self.module = module
for p in self.module.parameters():
if p.requires_grad:
p.register_post_accumulate_grad_hook(self._all_reduce_grad_hook)
def _all_reduce_grad_hook(self, param: torch.Tensor) -> None:
if param.grad is not None:
dist.all_reduce(param.grad, op=dist.ReduceOp.SUM)
param.grad /= dist.get_world_size()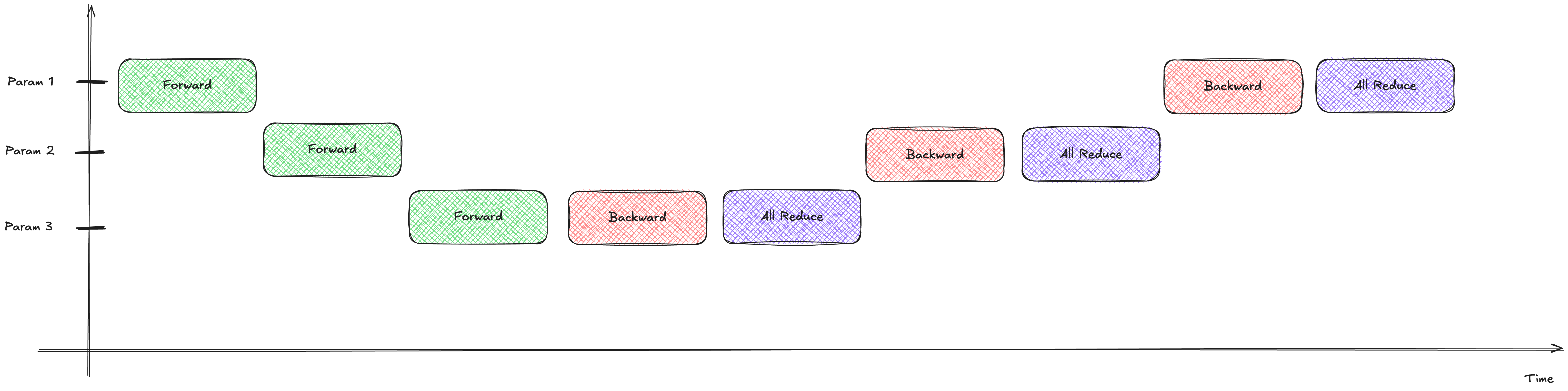 Now, as soon as a gradient is ready, we immediately fire off an all-reduce operation.
Now, as soon as a gradient is ready, we immediately fire off an all-reduce operation.
 The timeline looks better, but there’s a catch.
The timeline looks better, but there’s a catch.
The Problem: dist.all_reduce is a synchronous blocking call. Even though we start the communication earlier, the backward pass literally pauses and waits for the communication of that specific parameter to finish before moving on to compute the next gradient. We haven’t actually overlapped compute and communication; we’ve just interleaved them.
3. Overlapped Asynchronous DDP: Non-Blocking Communication
To truly overlap compute and communication, we need to tell PyTorch: “Hey, start this network transfer, but don’t wait for it to finish. Keep computing the next gradients!”
We can do this by passing async_op=True to our all-reduce call. This returns a “handle” that we can wait on later.
class OverlappedAsyncDDP(nn.Module):
def __init__(self, module: nn.Module) -> None:
super().__init__()
self.module = module
self.reduction_handles = []
# ... register hooks ...
def _all_reduce_grad_hook(self, param: torch.Tensor) -> None:
if param.grad is not None:
param.grad.data /= dist.get_world_size()
handle = dist.all_reduce(param.grad.data, op=dist.ReduceOp.SUM, async_op=True)
self.reduction_handles.append(handle)
@contextlib.contextmanager
def backward_and_sync(self):
yield # loss.backward() runs here
# Now we wait for all the async transfers to finish
for handle in self.reduction_handles:
handle.wait()
self.reduction_handles.clear()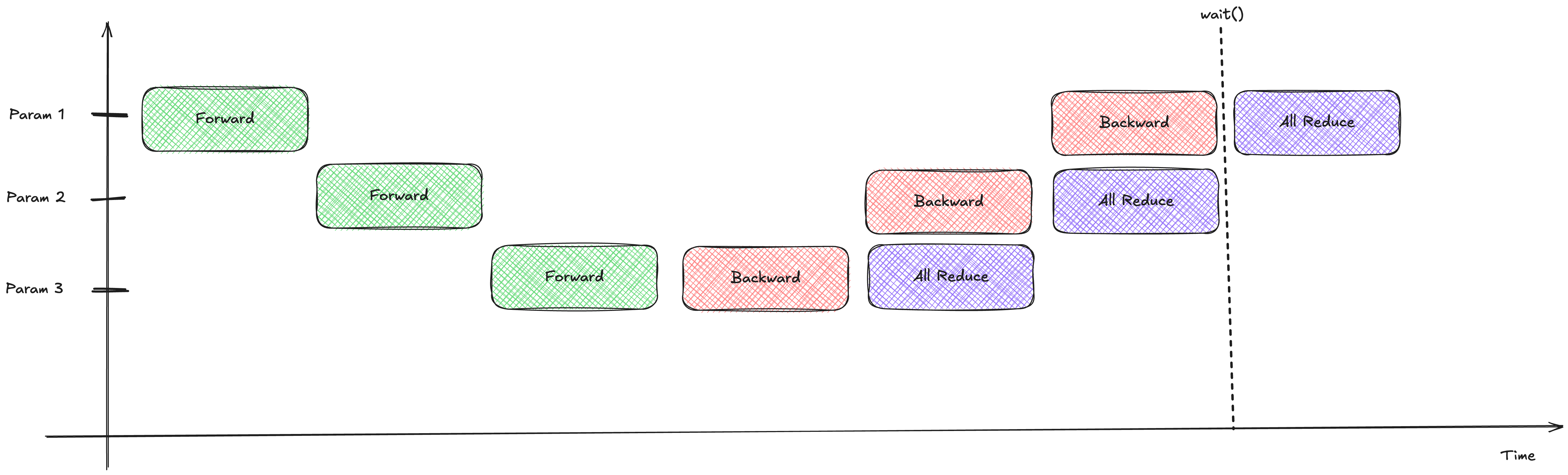 Beautiful! The backward pass continues chugging along while the network handles the all-reduce operations in the background.
Beautiful! The backward pass continues chugging along while the network handles the all-reduce operations in the background.
 Look at that overlap! Compute and communication are happening at the exact same time.
Look at that overlap! Compute and communication are happening at the exact same time.
The Problem: We are launching a separate all-reduce operation for every single parameter. If you have a model with 500 layers, you’re doing 500 tiny network transfers. Network operations have overhead. Sending 1000 tiny messages is much slower than sending 1 giant message.
4. Bucketed Overlap Asynchronous DDP: The Final Form
To minimize network overhead, we need to group our gradients into “buckets”. Instead of sending a parameter’s gradient as soon as it’s ready, we wait until a bucket is full, and then we send the whole bucket at once.
This is exactly what PyTorch’s native DDP does.
- We pre-allocate contiguous chunks of memory (buckets).
- We map each parameter’s
.gradattribute to a specific slice of a bucket. - As gradients are computed, they are written directly into the bucket.
- When all parameters in a bucket have their gradients ready, we fire a single asynchronous all-reduce for the entire bucket.
class Bucket:
def __init__(self, params, grad_data, bucket_size):
self.params = params
self.grad_data = grad_data
self.params_with_grads_ready = 0
self.handle = None
# Point param.grad to the bucket's contiguous buffer!
offset = 0
for p in self.params:
p_size = p.numel()
p.grad = self.grad_data[offset : offset + p_size].view(p.shape)
offset += p_size
def mark_param_ready(self, param):
self.params_with_grads_ready += 1
if self.params_with_grads_ready == len(self.params):
# Bucket is full! Fire the async all-reduce
self.grad_data /= dist.get_world_size()
self.handle = dist.all_reduce(self.grad_data, op=dist.ReduceOp.SUM, async_op=True)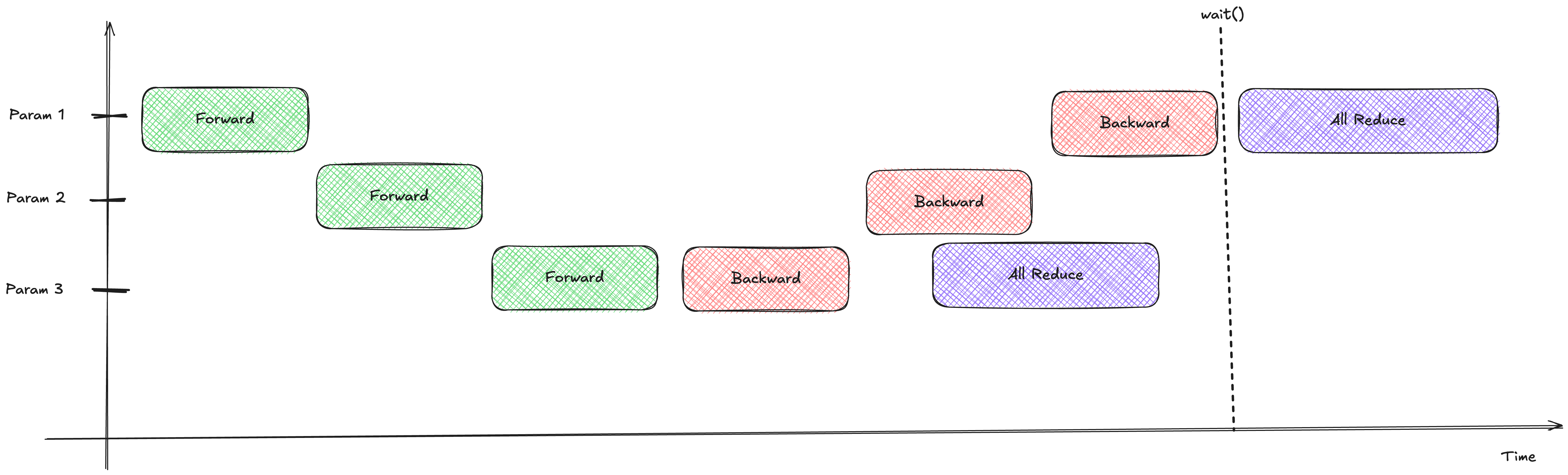 Gradients fill up the buckets. Once a bucket is full, it’s shipped across the network while the GPU continues computing the next bucket.
Gradients fill up the buckets. Once a bucket is full, it’s shipped across the network while the GPU continues computing the next bucket.
 This is peak efficiency. We have large, efficient network transfers perfectly overlapping with our backward pass compute.
This is peak efficiency. We have large, efficient network transfers perfectly overlapping with our backward pass compute.
(Bonus: If you look at the stream timeline below, you can see how using separate CUDA streams for communication can further optimize the scheduling on the GPU hardware itself!)
5. Stream Bucketed Overlap Asynchronous DDP: Squeezing Every Last Drop
We have a great bucketed asynchronous setup, but there’s one final hardware-level optimization we can make. Even though dist.all_reduce(..., async_op=True) is asynchronous from the CPU’s perspective, the actual GPU kernels for computation and communication might still end up waiting in the same default CUDA stream. A CUDA stream is a sequence of operations that execute in order on the GPU. If compute and communication are in the same stream, they can’t truly run in parallel on the GPU hardware.
To fix this, we can create a dedicated torch.cuda.Stream() just for communication! We use CUDA events to ensure the communication stream waits for the compute stream to finish filling the bucket before it starts the all-reduce.
class Bucket:
def __init__(self, params, grad_data, bucket_size):
# ... previous initialization ...
self.comm_stream = torch.cuda.Stream()
self.compute_ready_event = torch.cuda.Event()
def _all_reduce(self):
# 1. Record an event in the default compute stream
self.compute_ready_event.record(torch.cuda.current_stream())
# 2. Make the communication stream wait for this event
self.comm_stream.wait_event(self.compute_ready_event)
# 3. Launch the all-reduce in the dedicated communication stream
with torch.cuda.stream(self.comm_stream):
self.grad_data /= self.world_size
self.handle = dist.all_reduce(self.grad_data, op=dist.ReduceOp.SUM, async_op=True)
class StreamBucketedOverlapAsyncDDP(nn.Module):
# ...
@contextlib.contextmanager
def backward_and_sync(self):
yield
current_stream = torch.cuda.current_stream()
for bucket in self.buckets:
if bucket.handle is not None:
bucket.handle.wait()
bucket.reset()
# Ensure the main compute stream waits for the communication to finish
# before the optimizer step begins!
current_stream.wait_stream(bucket.comm_stream)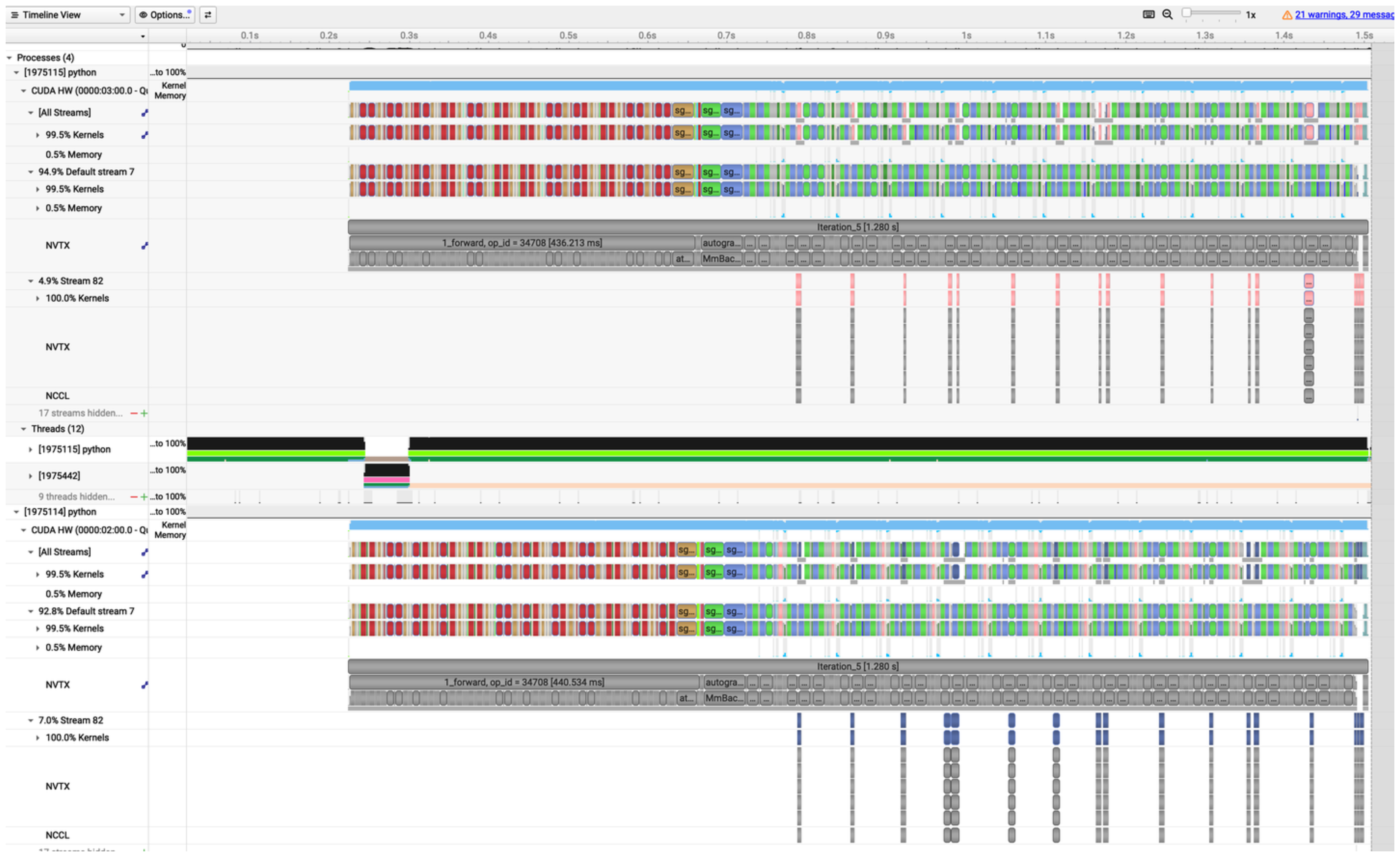 By explicitly managing CUDA streams, we guarantee that the GPU hardware can execute the communication kernels concurrently with the backward pass computation kernels.
By explicitly managing CUDA streams, we guarantee that the GPU hardware can execute the communication kernels concurrently with the backward pass computation kernels.
Code Implementation
I’ve implemented all these DDP variants (and more!) in MiniTitan, a lightweight distributed training framework built from scratch:
🔗 GitHub Repository: prabod/minititan
Conclusion
We’ve gone from a naive, sequential implementation to a highly optimized, bucketed, asynchronous engine with explicit CUDA stream management.
- Naive: Too slow, no overlap.
- Overlapped Sync: Better timing, but blocking calls ruin the overlap.
- Overlapped Async: True overlap, but too much network overhead from tiny messages.
- Bucketed Async: Large messages, great overlap.
- Stream Bucketed Async: Explicit CUDA streams ensure true hardware-level concurrency.
Next time you wrap your model in torch.nn.parallel.DistributedDataParallel, you’ll know exactly what kind of magic is happening under the hood to keep your GPUs blazing fast.